Digitalize your future
Upgrade your skills and boost your career

Alumni network
Employment rate
Hired within 6 months

Where our students get jobs
Get your dream job - we'll support you along the way!


Mijail Febres
Went from Scientist to Software Developer at Repower
❝Constructor Academy supported me effectively with assistance when preparing for my interviews.❞







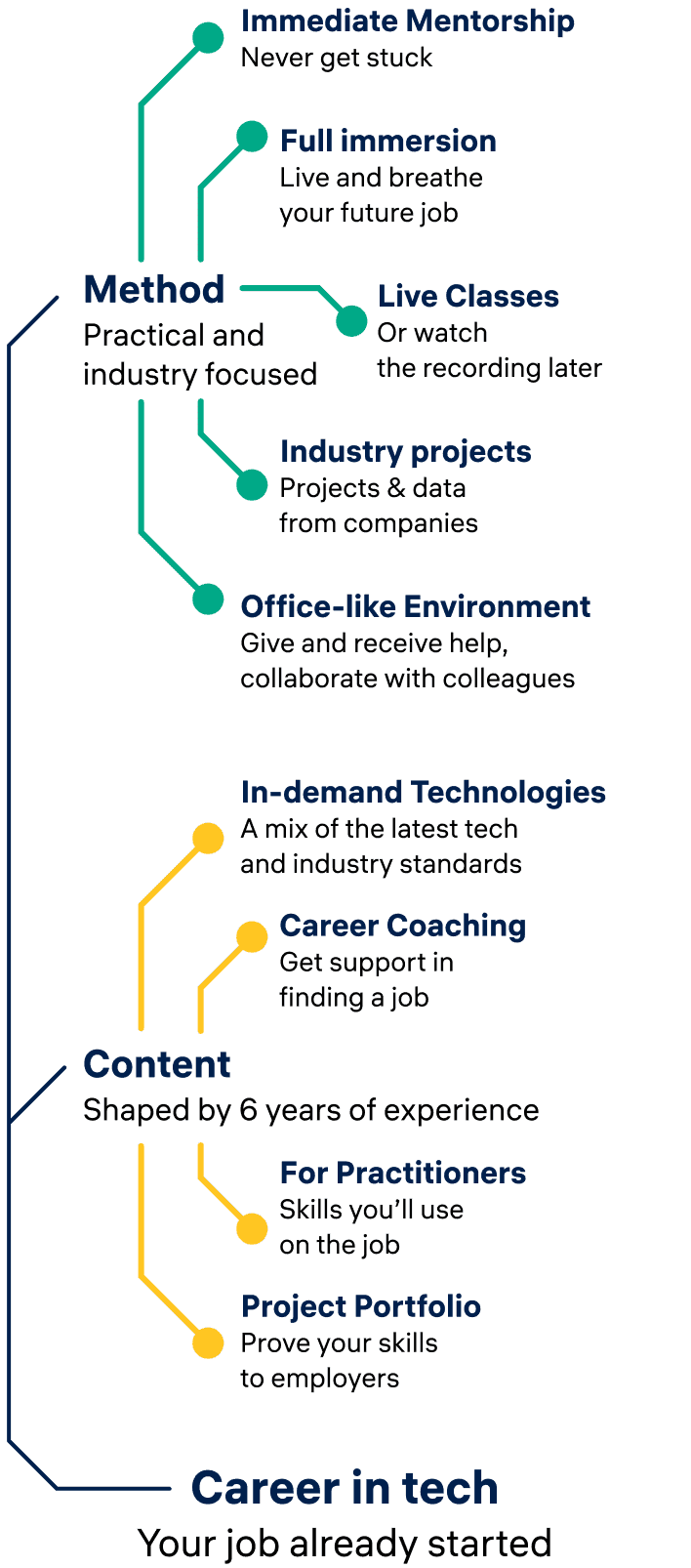
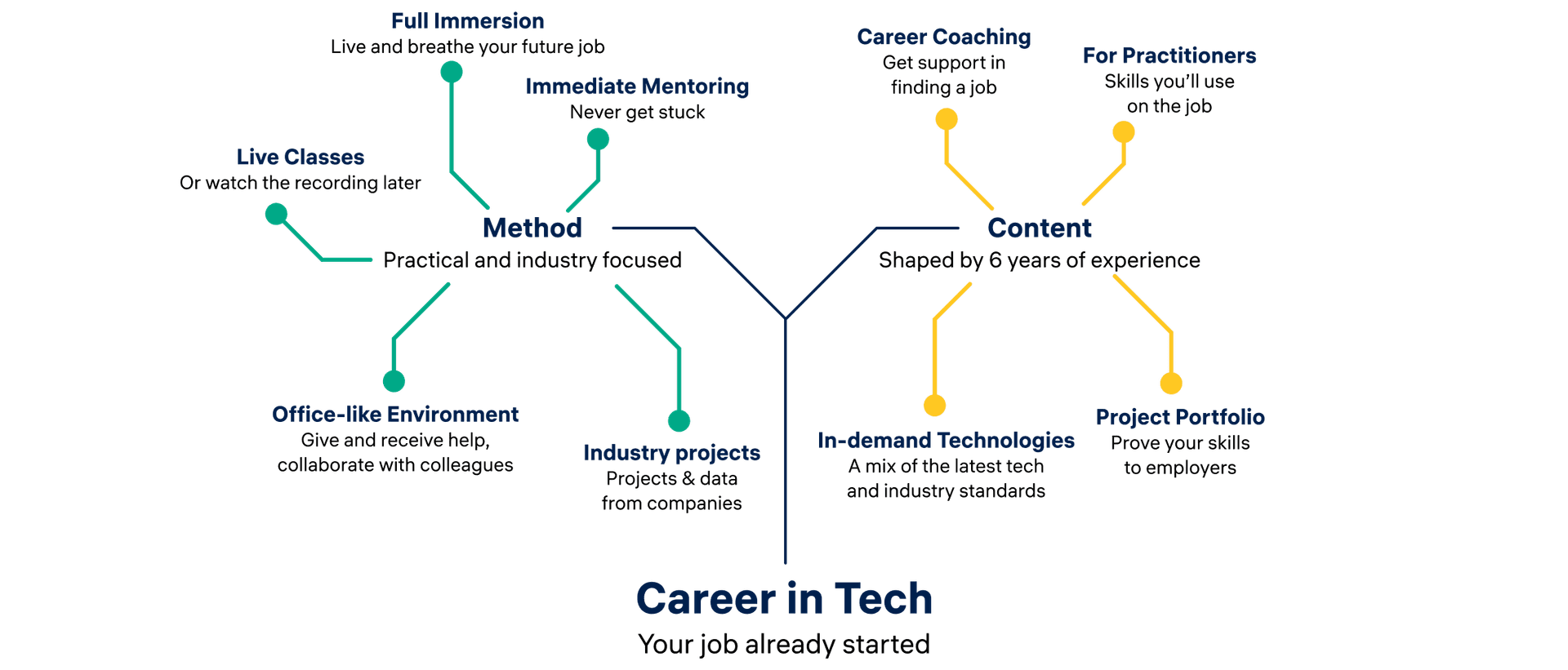
Unique Teaching Methods
At Constructor Academy, we use innovative teaching methods to provide an immersive learning experience. Our industry-experienced instructors offer a supportive environment with a mix of lectures, projects, and mentorship. Gain the skills you need to succeed in tech and upgrade your career.
Ready to change your career? Join us!
Who we are
Work hard, play hard. Learning new skills is as much about the knowledge you acquire, as it is a journey of personal growth. We provide a pleasant environment with frequent events and Apéros in which you can wind down from the challenges of the day and network with your fellow students and the team.


Our Locations
Zurich
Munich
Bremen
Remote
Programs
Bootcamps
- career change
- live lectures
- hands on
- industry projects
- job search coaching
- financing options
- lecture recordings
- lifelong access
- continuous mentorship
- On-site or online
Data Science
Master the basics of Machine Learning to forecast what’s next and predict patterns from large datasets using Python.
Full-Stack
Gain the skills to launch a career in web development, from JavaScript to Python. Build websites, APIs, interactive applications, and more.
Short Programs
- upskilling
- online
- live lectures
- part-time
- hands on
- evening classes
- financing options
Python Programming
Data Structures, scraping data from the web, APIs, databases, and generating automated reports.
Mastering Generative AI
Learn how generative AI models are built, and how to integrate them into applications and workflows.
Read more about Constructor Academy in our Blog
Read the latest news about Constructor Academy and get informed about all things around Programming and Data Science in Switzerland and Germany.



GPT model comparison guide
by Dipanjan Sarkar

Top data science bootcamps in Germany for 2024
by Constructor Academy

Top coding bootcamps in Germany 2024
by Constructor Academy